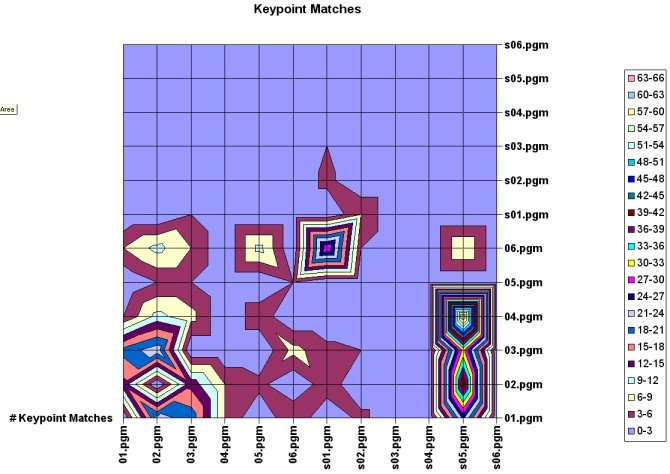
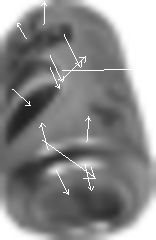
I tried applying the keypoint-matching portion of the SIFT paper to an input image but I did not achieve very good results. I matched two input images to my database of several hundred different soda-can images and typically achieved results as shown in the first picture. This seems to indicate that when a cluttered background is present, matching individual keypoints does not produce reliable results. The second image shows all of the keypoints found in the input image, which is around 400. It appears that keypoints are being generated for each soda-can in the input image but these are not being determined to be the closest-matching keypoints in the scene.
In order to further determine what the problem is, I tried matching a database image with a frame containing exactly the same image of the soda can in the database. Though this is definitely not a way to test a Computer Vision algorithm for classification ability, it gave some indication about why the poor matching results were occurring. Even though the same image was used, not all of the points were matched. This indicates that analyzing the constellation of points is very important when dealing with a cluttered background. Otherwise, the background could have so much variety to it that keypoints arising in it would match better than keypoints in the correct object. Lowe describes in his SIFT paper a process of using clusters of results from a generalized Hough Transform. Although Lowe achieved good matching results using just his keypoint matching algorithm, he used high-resolution images where the keypoints within the objects in question were numerous and apparently more distinguishable from the background, as seen with a book-matching example at this link: http://www.cs.ubc.ca/~lowe/keypoints/
The next step that I take might be to implement the generalized Hough Transform that Lowe mentions, followed by a pose-estimation. One concern I have is that there are not enough keypoints that can be matched to a database of images. In an earlier blog posting, I showed matching results from comparing high-resolution images to low-resolution images that were scaled-down and oriented differently. These results showed that sometimes there were no keypoint matches between different scales of soda cans. If I have to add many different soda-can scales as well as orientations to my database of images, then the matching algorithm might become prohibitively inefficient and the accuracy level might drop even lower.
I might try using PCA-SIFT to extract keypoints. This algorithm replaces the "smoothed-histogram" that Lowe uses in his keypoint creation stages with PCA (principal component analysis). The PCA-SIFT keypoints are supposedly better at handling noisy images but are more prone to localization error. I was also thinking about using the features described in the Video Google paper, but there is no indication as to how efficient the computation of the "visual words" is. The Video Google paper apparently assumes that the "visual words" are already computed in a video before objects are classified.
Perhaps a long-term solution to object detection using mobile robots should be to simply detect the presence of an object with no regard as to what type of object it is. Objects of a certain size, color, dimension etc. could then be inspected more closely where some SIFT variation could be applied. Perhaps eventually an entire scene could be constructed into a 3D model and while this process is taking place, some easy to recognize objects could be classified before the entire 3D reconstruction completes.
I think that for now, I will implement the generalized Hough Transform and the other stages mentioned in Lowe's SIFT paper and see under what conditions soda cans can be recognized well. I will then be able to better determine if enough keypoints are being generated. I will also be able to determine where Adaboost fits in the detection/recognition process.