I have a new set of Milestones to accomplish for this quarter. I'm very busy this quarter so I will try to accomplish as many of them as I can.
Understand SIFT thoroughly - meet by 5/10/06The purpose of this milestone is to understand SIFT well enough to be able to set up an appropriate training set and to plan out specific implementation details. This will include locating existing SIFT-related source code and determining what software should be used (i.e. shell-scripting, ImageMagick, Matlab, OpenCV, C++ etc.). Last quarter, I implemented everything in Matlab first before attempting to implement it in C++. This quarter, I will be giving C/C++ preference and use Matlab to aid in my understanding of SIFT or to generate charts, graphs etc. I've found shell scripting to be incredibly helpful in all aspects of programming --not just for this research.
Create the Training Set - meet by 5/17/06This will most likely involve modifying my existing training set. This training set consists of extracted images of soda cans acquired at a single scale, against a static background, under constant lightining conditions, and two separate orientations. Although the use of this training set will most likely not result in scale-invariant keypoints, it will be useful in testing other aspects of this SIFT algorithm directly against my Adaboost implementation. Invariance to background clutter, lighting, performance while in motion, and efficiency can be tested using this training set. After a working SIFT implementation is created, a training set that includes soda cans extracted under a wider variety of conditions can later be swapped with this training set. I figure that I will go through all of the steps required to apply SIFT using only a few images. Once this is done, I will have a better idea about how to create a good training set for SIFT. Last quarter, I had to redo my training set several times so I want to avoid having to do that this quarter.
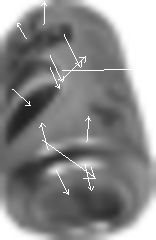
Detect Keypoints- meet by 5/24/06This will involve using a difference-of-gaussian function to search the scale-space of the soda can training images to identify scale-invariant interest points. The most stable keypoints will then be selected and assigned orientations based on their local gradient directions. These gradients will then be transformed into a representation that is resistant to shape distortion and illumination differences. This will be accomplished using an existing binary implementation, such as the version provided by David Lowe on his website. I will probably make a primitive algorithm for matching keypoints initially and then improve upon it.
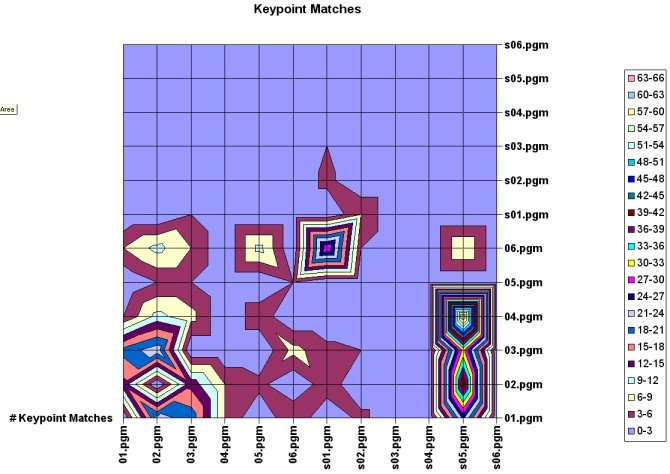
Match Keypoints of New Input Images (no background clutter) - meet by 5/31/06A database of keypoints from the training images will first be set up. A new input image will be matched with this database by finding the Euclidean distance between the feature vector of the input image and the feature vectors in the database. The new input images will include soda can images with backgrounds that have been manually removed so that no keypoints will be detected outside of the soda can regions. If background clutter is left
in, then keypoints extracted from these regions may yield so many negative classifications that false negative classifications will result even when a soda can is present in a particular region. Without background clutter, I can test keypoint matching without having to cluster the keypoints or apply any additional transformations to them.
Identify Keypoint Clusters, Apply Further Filtering of Keypoint Matches (background clutter added) - meet by 6/7/06This will first filter correct keypoint matches from the false matches by identifying clusters of three or more keypoints that agree on the orientation, scale, and location of the detected object. This is described in Lowe’s SIFT paper with a Hough Transform offered as a solution to identifying these clusters. Next, a least-squares estimate will be applied for an affine approximation to the object pose. Further analysis can be applied, as described by Lowe, to determine the probability that a particular set of features is the object being searched for.
Run Detection Method Live - meet by 6/14/06Once a SIFT implementation is successfully implemented, it will be tested using live video footage. Initially, I might try using the same setup that I used before with the same static background. The results from this test will be compared with my previous results based on the efficiency and accuracy of detection. Various conditions will then be changed, such as the ambient lighting. Video footage will then be tested while the camera is moving horizontally with respect to the soda cans. The complexity of the tests will be gradually increased and the results analyzed unless/until the SIFT implementation begins to perform poorly. If time permits, a new set of training images will be acquired using soda cans positioned in a variety of locations and orientations and this SIFT implementation will be retested. Depending on the availability of SIFT source code online, some of these milestones can be combined and their theoretical completion dates moved back or forward.