Running the Keypoint Detector
I downloaded the keypoint detection code from David Lowe's website:
http://www.cs.ubc.ca/~lowe/keypoints/
David Lowe is the creator of SIFT. The code is in binary format and was extremely easy to run in Linux. There are apparently no required libraries or dependencies to run this code. I took some photos with a digital camera and cropped out the regions containing soda cans from the background. From what I've seen so far, it appears that SIFT detects keypoints that represent characteristics within an object. I believe this means that the outline of a soda can cannot be taken into account for object detection. This may prove to be a problem if objects to be detected do not have many detailed features. To test the validity of this theory, I would like to try spray-painting a soda can a solid color and see if any SIFT keypoints are extracted. Here are some images of detected keypoints:
SCALED TO DOWN TO 1.5%:

SCALED TO DOWN TO 1.5% THEN SCALED UP TO 600%:


SCALED TO DOWN TO 3.0%:

SCALED TO DOWN TO 3.0% THEN SCALED UP TO 600%:


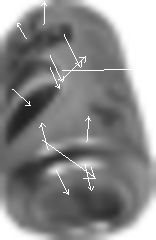

These cans all started out as high resolution images. These images were then scaled down to 1.5% or 3.0% of their resolution in an attempt to simulate soda cans at a typical scale encountered in live video footage. According to Lowe's README file that came with the keypoint detection code, more keypoints can be detected if an image is first scaled to a larger size. In fact, the number of detected keypoints typically doubled when a low resolution image was scaled up. The pepsi cans with a prominant logo yielded the most keypoints. The soda can in the top-most image yielded no keypoints at all. There are many cases where the specular highlights appeared to yield keypoints. These cases would be taken care of at a later stage where keypoints from different training images taken under different lighting conditions would be analyzed to determine which keypoints are invariant to scale and lighting. The more I think about it, the more appealing a hybrid solution to object detection seems --one that would incorporate data from multiple sources to arrive at a conclusion. For instance, perhaps some sort of texture recognition or color detection method could be used in conjunction with SIFT to detect objects with sparse and dense features. I will continue to investigate how SIFT can be applied to soda can detection and find out what image resolutions I have to work with. If SIFT proves to work well for objects up close, I might use some other methods to detect objects of interest and then proceed to zoom-in on those objects before applying SIFT.
The next step will be to test out keypoint matching between these detected keypoints.
2 comments:
Howdy! I know this is somewhat off topic but I was wondering which blog platform are you using for this website?
mlsu ba 2nd year result 2021-22 subject wise
Post a Comment