 When I had finished extracting soda-can images for my training set, I had 410 vertical and 420 horizontal soda can images. I then randomly offset each of these images by up to 1/8 of their width and 1/4 of their height to generate a total of 4444 positive training examples of vertically-oriented soda cans and 4554 positive training examples of horizontally-oriented soda cans --as Dlagnekov did in his thesis.
When I had finished extracting soda-can images for my training set, I had 410 vertical and 420 horizontal soda can images. I then randomly offset each of these images by up to 1/8 of their width and 1/4 of their height to generate a total of 4444 positive training examples of vertically-oriented soda cans and 4554 positive training examples of horizontally-oriented soda cans --as Dlagnekov did in his thesis.I then trained two classifiers using 23200 negative training examples for each. Instead of using the entire labeled image, I constrained my negative training examples to a 161x184 pixel subwindow in the bottom-center of the image. Furthermore, I used negative training examples from video footage that contained no soda-cans to begin with --rather than extracting negative examples from labeled images that exclude areas marked as containing soda cans. The first classifier used only the vertically-oriented soda-can images with a detection-window-size of 17x27 pixels and the second classifier used only the horizontally-oriented soda-can images with a detection-window-size of 30x14 pixels. The I then modified the existing license plate detection code to read in a list of classifiers from a file and run them sequentially on the source video.
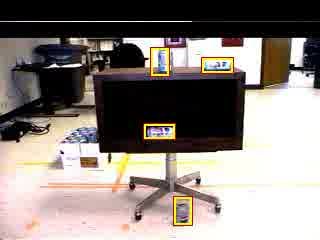
Using this new framework, I ran my detection algorithm on a sample video that I had set aside before training. This sample video footage was taken using the same background that was used to build the training set. Every soda can in the video was detected very accurately with no false-positives. The worst detection in this frame is probably the upper-left where the detection window is off-center. This is probably due to the fact that the detected locations are clustered, which might be causing surrounding detection areas to average to an off-center detection area. The next step is to test this algorithm on ROBART III using live video footage.
No comments:
Post a Comment